
As a typical IT department, we log a lot data. Loads of it. Thanks to various regulatory requirements, we need to log more and more data from more and more sources. That’s a lot of mores! We are also required to mine more information from those logs, and need keep these logs in their original form for longer periods in case they are required for further analysis, forensic investigation or litigation purposes.
So how do you keep a lid on a data type that grows relentlessly by multiple gigabytes per day?
In this article I will explain some common logging strategies, and outline the significant gains I have experienced using Data Deduplication. I will be referring to Microsoft Forefront TMG log files, but similar settings and concepts apply for other systems.
Logging Options (What, How and Where)
When configuring your logging settings, you have a few options.
What to log?
When thinking of logging it is tempting to log everything. Then once you realize just how much data that is, you might be tempted to log “only the important stuff”. The sweet spot is somewhere in the middle, probably close to the defaults.
The rule of thumb here is that you can easily discard records later if you do not need them, but you cannot regenerate the data if you were supposed to log it but you missed it. Rather err on the side of more than less.
How to log
Logging to flat file or to text makes your logs easily portable between multiple systems and reporting tools. You may need to retrieve today’s log file three years from now, so having your log data in a portable form that can be used on other systems rather than just the proprietary source is useful. This is especially true with the now discontinued Forefront TMG. Accessing W3C text files will be much easier than accessing the ageing or uninstalled SQL Express log database in the future.
Where to log, store and archive.
Logging to the local device has many advantages but it is not a great place to store logs for the longer term.
Storage refers to a place where you keep the logs, knowing you will be using them in the short term. An example of this would be to generate weekly reports.
Archiving on the other hand, generally refers to long term “in case we need it” storage.
A quick example of how this fits together is that you could log to your local TMG server, store in a Vantage storage, and archive to a file share.
The location of the log files also affects how easily you can use them. Having the logs stored on the TMG server as a permanent location means you always need to access the TMG server to get to the logs, this in turn has a negative performance impact on the TMG server.
NTFS compression
When specifying storage limits you need to consider the amount of storage available on the TMG server itself. It is very tempting to use the “Compress log files” checkbox. This invokes NTFS compression on the log files. This is effective at reducing the amount of space required to store your logs but it comes with considerable performance overhead.
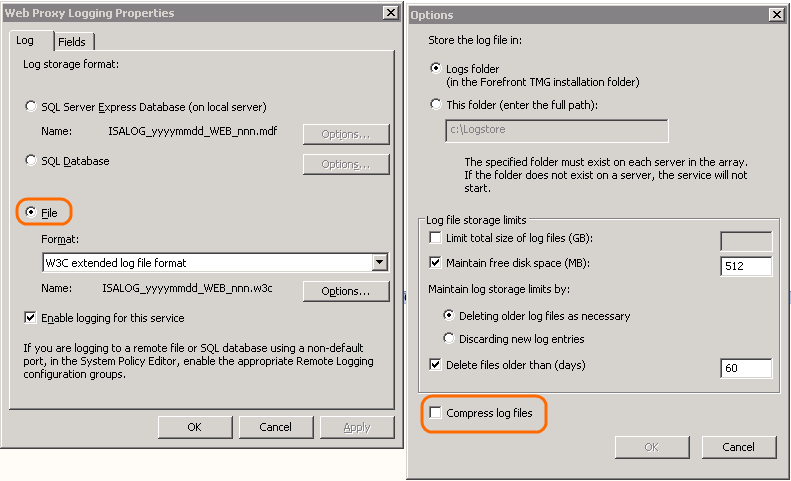
This built in Windows feature allows you to seamlessly compress files and use them as if they are not compressed in a separate archive such as a zip file.
When it comes to log files the typical gain you see is about a 50%- 55% reduction on disk space. The problem here is that the compression is done “on the fly” and every time data is written to or read from the file the NTFS driver needs to decompress and re-compress.
As an example, even if you copy a compressed file from one location to another on the same server it will be decompressed, copied, and then re-compressed. Since the process is resource intensive, this has an impact on the overall system performance.
The problem gets even worse if you consider that the files need to be decompressed when copied over the network. So NTFS compression will not even help you out there either. In fact, all that will happen is that you will end up with a slow copy that hits the CPU of the source server.
Data Deduplication
Data Deduplication (commonly shortened or know as de-dupe) is a method for reducing the amount of disk space required for storage. It varies from other compression strategies in that de-dupe is a storage block level optimization and not a file level compression.
All of your data is written as storage blocks on disk. Data Deduplication finds duplicate blocks and references those with reparse points rather than keeping multiple copies of the same block data. Data Deduplication does not actually compress your data, it reduces the space requirement by eliminating duplication.
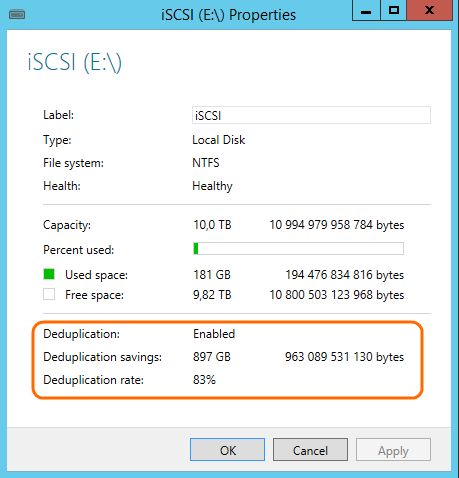
Depending on the data type you can expect certain disk savings. In the case of Forefront TMG log data or a WebSpy Vantage Storage the saving is in the 80% – 85% range.
As a real world example, 1.02TB of data only consumes 26.8GB of actual disk space. The deduplication rate is 83% and the saving is 897GB. In other words it’s a HUGE saving.
With Data Deduplication, data is not compressed on the fly. It is written in its full size. Depending on the de-dupe rules you have specified, a grovel process will execute in the background and start to deduplicate the new data. Because there is no “on the fly” process there is no write performance penalty.
When data that has been deduplicated is read, the blocks are called from the de-dupe location referenced by a reparcer pointer. These will then be stored in cache until they cool down. This has the benefit of significantly speeding up reads and repetitive reads from a de-dupe data store.
So basically, NTFS compression is really bad. Data Deduplication is really good.
How to Configure Data Deduplication
Microsoft is quite vocal about the very low minimum resource requirement for Data Deduplication. As a minimum, you need Windows Server 2012 or newer and a separate volume. That is any drive that is not the C:\ drive and it must be formatted with NTFS.
To configure Data Deduplication:
- From the Server Manager, install the Data Deduplication Role via the Add roles and features Wizard
- Select File and Storage Services | Volumes and right click the NTFS volume you want to configure as a deduplication volume
- Click Configure Deduplication and set the Data deduplication setting to General Purpose file server
- Accept the default setting and continue.
Alternatively you can explore the settings to familiarize yourself. Setting the Deduplicate files older than (in days) to 0 ensures all files are deduplicated on the schedule regardless of the age.
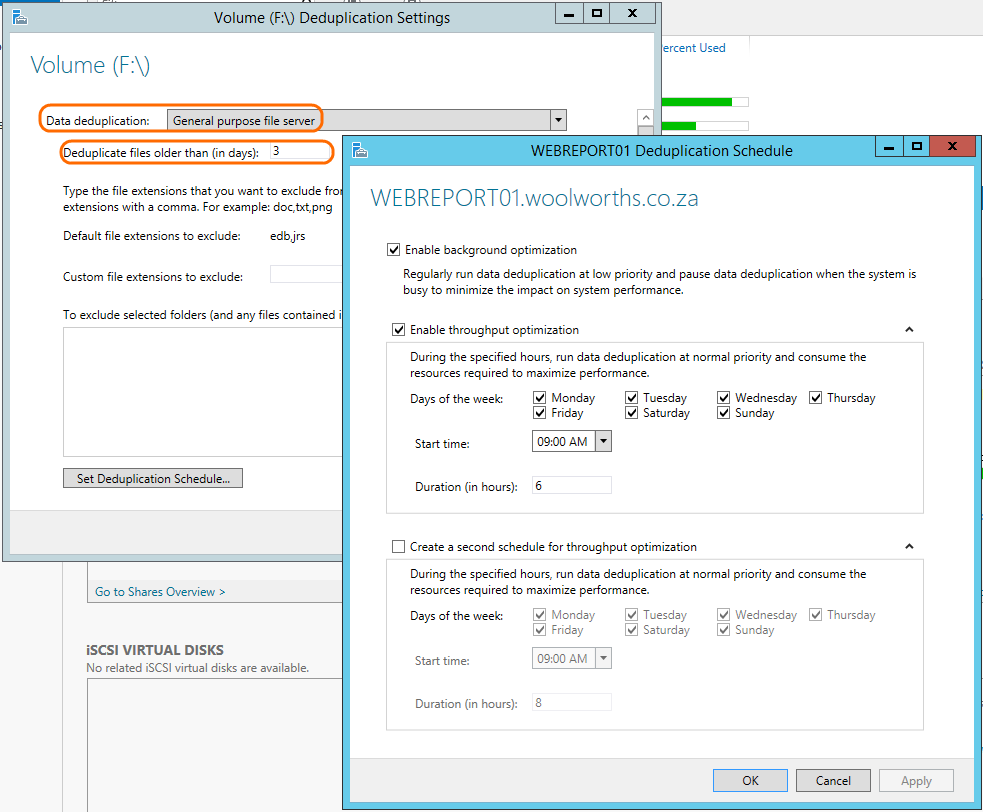
After Data Deduplication has been configured, you should see that the deduplication fields are populated in the volumes view. Now all you have to do is sit back and wait for the Data Deduplication process to kick off and do its thing.
Putting it all together
Here is a typical real world scenario for logging, storage and archiving:
- 2 x Forefront TMG servers log to file on local disk storing a maximum of 7 days
- Daily scheduled task copies the log files to a Windows Server share on a volume with Data Deduplication enabled
- Vantage task imports the logs with a relative date filter for past 1 day
- Vantage task purges data older than 31 Days
The result is that you have a 7 day cache of logs on each Forefront TMG Server should anything go wrong with the rest of the process. This is the logging location.
You have a 1 month working set of log storage to work with in WebSpy Vantage. This is your storage location or “working dataset”.
The original files on the deduplicated volume are your long term archive.
With a projection of 1TB of log data being added per month, a 10TB disk would run out of space in less than a year. With Data deduplication enabled we only expect to be consuming about 2TB of disk after a year. This means we are set for about 5 years, which well exceeds the 3 year maximum retention period that is required.
All of this is achieved on the existing Vantage server without requiring any additional storage.
Further Reading
To get a more granular explanation of how deduplication works http://blogs.technet.com/b/filecab/archive/2012/05/21/introduction-to-data-deduplication-in-windows-server-2012.aspx
To find out more of the evils of NTFS compression http://support.microsoft.com/kb/251186